December 5, 2025
Flexible Streaming Ingest, Web App Integration, and Infra Visibility Upgrades. This two-week release pushes MooseStack forward on three fronts: flexible high-volume ingestion, developer experience for full-stack apps, and operational visibility.
Moose gained the ability to handle arbitrary JSON ingest, Kafka-backed streaming, IcebergS3 for data lake integration, and powerful modeling tools like materialized columns and per-column codecs. Meanwhile, Fiveonefour added storage visualizations so teams can see how their data grows.
Highlights
- New: Kafka engine support for real-time ClickHouse ingestion
- New: IcebergS3 engine for Apache Iceberg data lake integration
- New: Materialized columns for precomputed fields at ingestion time
- New: Fastify web app template with automatic async initialization
- New: Fiveonefour database storage visualization for capacity planning
Moose
Kafka engine support for streaming ingestion
Define tables with ClickHouse's Kafka engine as an alternative consumer that reads directly from Kafka topics into ClickHouse, bypassing Moose's built-in streaming consumer. Use materialized views to transform and route the data. This is an experimental engine from ClickHouse.
// Create a Kafka engine table that consumes from a topicexport const KafkaSourceTable = new OlapTable<KafkaTestEvent>( "KafkaTestSource", { engine: ClickHouseEngines.Kafka, brokerList: "redpanda:9092", topicList: "KafkaTestInput", groupName: "moose_kafka_consumer", format: "JSONEachRow", },);PR: #3066 | Docs: OlapTable | ClickHouse Kafka Engine
IcebergS3 engine for data lake storage
Configure tables on Apache Iceberg with S3 storage.
export const AnalyticsEventsTable = new OlapTable<AnalyticsEvent>( "AnalyticsEvents", { engine: ClickHouseEngines.IcebergS3, path: "s3://my-data-lake/analytics/events/", format: "Parquet", awsAccessKeyId: "{{ AWS_ACCESS_KEY_ID }}", awsSecretAccessKey: "{{ AWS_SECRET_ACCESS_KEY }}", compression: "zstd", },);PR: #2978 | Docs: OlapTable | ClickHouse Iceberg Engine
Materialized columns in data models
Define materialized columns to automatically compute derived values at ingestion time—date extractions, hash functions, JSON transformations—without separate aggregations.
Why it matters: Cheaper, faster queries at scale. Materialized columns move expensive expressions into ingestion time so queries become simple scans over precomputed fields. This directly impacts infrastructure cost and query latency for time-series, metrics, and logs.
export interface MaterializedTest { id: Key<string>; timestamp: DateTime; userId: string; // Materialized columns - computed at ingestion time eventDate: string & ClickHouseMaterialized<"toDate(timestamp)">; userHash: UInt64 & ClickHouseMaterialized<"cityHash64(userId)">;}PR: #3051 | Docs: Supported types | ClickHouse Materialized Columns
Fastify web app template
New project template demonstrating Fastify framework with Moose, plus fixed WebApp support for Fastify's async initialization.
moose init --name <project-name> --template typescript-fastifyPR: #3068, #3061 | Docs: Fastify integration | Fastify template
Other improvements
- Arbitrary JSON fields in ingest APIs – Accept payloads with extra fields beyond your schema; extras land in a JSON column for flexible schema evolution. PR #3047 | Data models
- Custom PRIMARY KEY expressions – Define custom PRIMARY KEY with hash functions like
cityHash64for better data distribution in high-cardinality scenarios. PR #3031 | ClickHouse Primary Keys - Per-column compression codecs – Apply per-column compression codecs (ZSTD, LZ4, Delta, Gorilla, and others) using
ClickHouseCodec<"...">type annotations. PR #3035 | ClickHouse Compression - Python LSP autocomplete for SQL – Get IDE autocomplete for column names in f-strings using
MooseModelwith{Column:col}format. PR #3024 - Next.js client-only mode (experimental) – Set
MOOSE_CLIENT_ONLY=trueto import Moose data models without runtime, fixing HMR errors. PR #3057 | API Frameworks - Web apps in
moose ls– List web applications alongside tables, streams, and APIs withmoose ls --type web_apps. PR #3054 - Lifecycle inheritance in IngestPipeline – Top-level lifecycle settings automatically propagate to table, stream, and deadLetterQueue components, reducing config duplication. PR #3088
- MCP query result compression – Results compressed using toon format for better IDE/AI integration performance. PR #3033
- Renamed --connection-string to --clickhouse-url – CLI now uses
--clickhouse-urlfor ClickHouse commands (old flag still works). Improved connection string parsing for native protocol URLs. PR #3022
Bug fixes
- Security updates in templates – Updated Next.js (15.4.7 -> 16.0.7) and React (19.0.0 -> 19.0.1) to patch security vulnerabilities in frontend templates. #3089
- MCP template build failures – Fixed missing/empty
.npmrcfiles that causednpm installand Docker builds to fail when creating new MCP server projects. #3084, #3082, #3081 - MCP SDK compatibility – Updated MCP template to work with SDK v1.23+ which changed its TypeScript types. Migrated to new
server.toolAPI with Zod validation. #3075 - ORDER BY parsing with projections – Fixed incorrect ORDER BY extraction when tables contain projections. The CLI was picking up projection ORDER BY clauses instead of the main table's. #3052
- Array literals in views – Views containing ClickHouse array syntax like
['a', 'b']would fail to parse. Added fallback parser to handle ClickHouse-specific SQL. #3034 - LowCardinality columns in peek/query –
moose peekandmoose queryfailed on tables withLowCardinality(String)columns. Switched to HTTP-based ClickHouse client which supports all column types. #3025 - DateTime precision preservation – JavaScript Date objects drop microseconds/nanoseconds. Added
DateTimeStringandDateTime64String<P>types that keep timestamps as strings to preserve full precision. #3018
Fiveonefour
Database storage visualization (experimental)
New experimental page showing table storage usage over time with interactive charts. When enabled, a "Database" tab appears in your branch navigation with per-table storage area charts, date range filters, and granularity options (minute/hour/day).
Why it matters: Watch storage growth over time. Time-series charts of table sizes are crucial for capacity planning, catching runaway growth, and understanding which workloads drive storage cost.
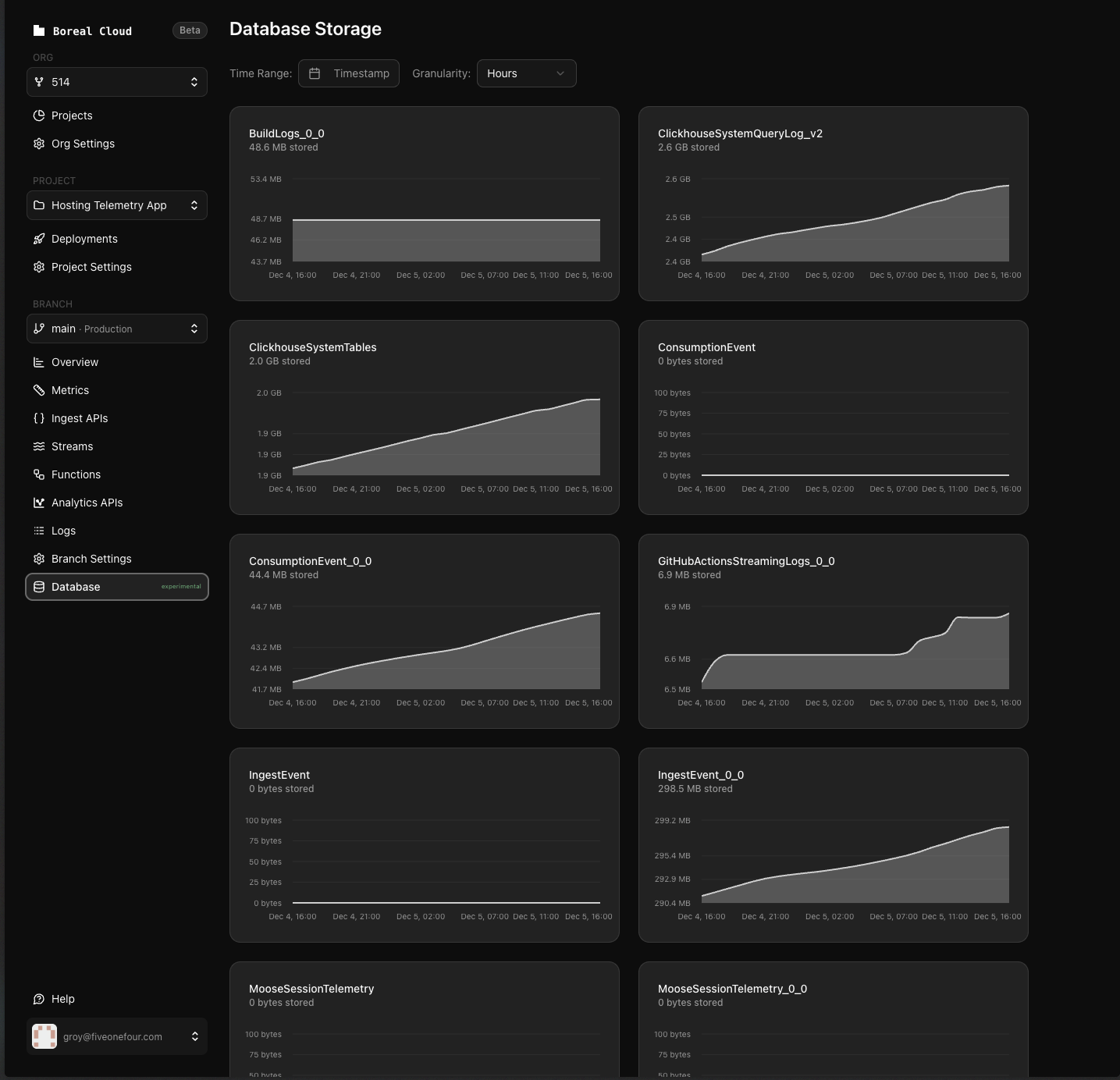
This feature is behind an experimental flag. Contact support to enable it for your organization.
Other improvements
- Log drain performance – Reuses database connections instead of creating new ones per batch, reducing connection overhead.
- ClickHouse query performance – Optimized table structure and indexing for faster loading of query performance data.
- Temporarily removed "Build from Existing Database" – Option removed from project creation flow while being improved. Users can still import from GitHub or templates.
Infrastructure
- Extended deployment startup timeouts – Increased from 60 to 180 seconds to reduce failures for larger applications during high-load periods.
Bug fixes
- GitHub authentication – Fixed issues preventing repository connections and operations.
- Security updates – React 19.2.0 -> 19.2.1, Next.js 16.0.1 -> 16.0.7.
- Function names display – Fixed missing function names in metrics table.